
PROCESS MANAGEMENT AND VARIOUS SHELLS
Process
A process is basically a program in execution. The
execution of a process must progress in a sequential fashion.
A process is defined as an entity which represents
the basic unit of work to be implemented in the system.
To put it in simple terms, we write our computer
programs in a text file and when we execute this program, it becomes a process
which performs all the tasks mentioned in the program.
When a program is loaded into the memory and it
becomes a process, it can be divided into four sections ─ stack, heap, text and
data. The following image shows a simplified layout of a process inside main
memory –

Component
& Description
1 Stack
The process Stack contains the temporary data such
as method/function parameters, return address and local variables.
2 Heap
This is dynamically allocated memory to a process
during its run time.
3 Text
This includes the current activity represented by
the value of Program Counter and the contents of the processor's registers.
4 Data
This section contains the global and static
variables.
Process
Life Cycle
When a process executes, it passes through different
states. These stages may differ in different operating systems, and the names
of these states are also not standardized.
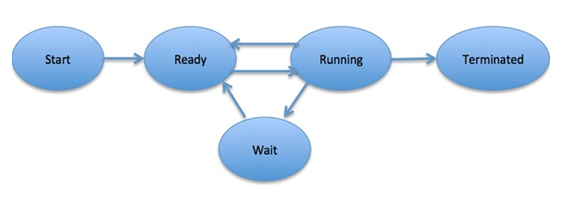
In general, a process can have one of the following
five states at a time.
S.N. State
& Description
1 Start
This is the initial state when a process is first
started/created.
2 Ready
The process is waiting to be assigned to a
processor. Ready processes are waiting to have the processor allocated to them
by the operating system so that they can run. Process may come into this state
after Start state or while running it by but interrupted by the scheduler to
assign CPU to some other process.
3 Running
Once the process has been assigned to a processor by
the OS scheduler, the process state is set to running and the processor
executes its instructions.
4 Waiting
Process moves into the waiting state if it needs to
wait for a resource, such as waiting for user input, or waiting for a file to
become available.
5 Terminated
or Exit
Once the process finishes its execution, or it is
terminated by the operating system, it is moved to the terminated state where
it waits to be removed from main memory.
Process
Control Block (PCB)
A Process Control Block is a data structure
maintained by the Operating System for every process. The PCB is identified by
an integer process ID (PID). A PCB keeps all the information needed to keep
track of a process as listed below in the table −
Information
& Description
1 Process
State
The current state of the process i.e., whether it is
ready, running, waiting, or whatever.
2 Process
privileges
This is required to allow/disallow access to system
resources.
3 Process
ID
Unique identification for each of the process in the
operating system.
4 Pointer
A pointer to parent process.
5 Program
Counter
Program Counter is a pointer to the address of the
next instruction to be executed for this process.
6 CPU
registers
Various CPU registers where process need to be
stored for execution for running state.
7 CPU
Scheduling Information
Process priority and other scheduling information
which is required to schedule the process.
8 Memory
management information
This includes the information of page table, memory
limits, Segment table depending on memory used by the operating system.
9 Accounting
information
This includes the amount of CPU used for process
execution, time limits, execution ID etc.
10 IO
status information
This includes a list of I/O devices allocated to the
process.
The architecture of a PCB is completely dependent on
Operating System and may contain different information in different operating
systems. Here is a simplified diagram of a PCB –

The PCB is maintained for a process throughout its
lifetime, and is deleted once the process terminates.
Definition
The process scheduling is the activity of the
process manager that handles the removal of the running process from the CPU
and the selection of another process on the basis of a particular strategy.
Process scheduling is an essential part of a
Multiprogramming operating systems. Such operating systems allow more than one
process to be loaded into the executable memory at a time and the loaded
process shares the CPU using time multiplexing.
Process
Scheduling Queues
The OS maintains all PCBs in Process Scheduling
Queues. The OS maintains a separate queue for each of the process states and
PCBs of all processes in the same execution state are placed in the same queue.
When the state of a process is changed, its PCB is unlinked from its current
queue and moved to its new state queue.
The Operating System maintains the following
important process scheduling queues −
• Job
queue − This queue keeps all the processes in the system.
• Ready
queue − This queue keeps a set of all processes residing in main memory, ready
and waiting to execute. A new process is always put in this queue.
• Device
queues − The processes which are blocked due to unavailability of an I/O device
constitute this queue.

The OS can use different policies to manage each
queue (FIFO, Round Robin, Priority, etc.). The OS scheduler determines how to
move processes between the ready and run queues which can only have one entry
per processor core on the system; in the above diagram, it has been merged with
the CPU.
Two-State Process Model
Two-state process model refers to running and
non-running states which are described below −
State & Description
1 Running
When a new process is created, it enters into the
system as in the running state.
2 Not
Running
Processes that are not running are kept in queue,
waiting for their turn to execute. Each entry in the queue is a pointer to a
particular process. Queue is implemented by using linked list. Use of
dispatcher is as follows. When a process is interrupted, that process is
transferred in the waiting queue. If the process has completed or aborted, the
process is discarded. In either case, the dispatcher then selects a process
from the queue to execute.
Schedulers
Schedulers are special system software which handle
process scheduling in various ways. Their main task is to select the jobs to be
submitted into the system and to decide which process to run. Schedulers are of
three types −
• Long-Term
Scheduler
• Short-Term
Scheduler
• Medium-Term
Scheduler
Long Term Scheduler
It is also called a job scheduler. A long-term
scheduler determines which programs are admitted to the system for processing.
It selects processes from the queue and loads them into memory for execution.
Process loads into the memory for CPU scheduling.
The primary objective of the job scheduler is to
provide a balanced mix of jobs, such as I/O bound and processor bound. It also
controls the degree of multiprogramming. If the degree of multiprogramming is
stable, then the average rate of process creation must be equal to the average
departure rate of processes leaving the system.
On some systems, the long-term scheduler may not be
available or minimal. Time-sharing operating systems have no long term
scheduler. When a process changes the state from new to ready, then there is
use of long-term scheduler.
Short Term Scheduler
It is also called as CPU scheduler. Its main
objective is to increase system performance in accordance with the chosen set
of criteria. It is the change of ready state to running state of the process.
CPU scheduler selects a process among the processes that are ready to execute
and allocates CPU to one of them.
Short-term schedulers, also known as dispatchers,
make the decision of which process to execute next. Short-term schedulers are
faster than long-term schedulers.
Medium Term Scheduler
Medium-term scheduling is a part of swapping. It
removes the processes from the memory. It reduces the degree of
multiprogramming. The medium-term scheduler is in-charge of handling the
swapped out-processes.
A running process may become suspended if it makes
an I/O request. A suspended processes cannot make any progress towards
completion. In this condition, to remove the process from memory and make space
for other processes, the suspended process is moved to the secondary storage.
This process is called swapping, and the process is said to be swapped out or
rolled out. Swapping may be necessary to improve the process mix.
Comparison
among Scheduler
Long-Term Scheduler Short-Term
Scheduler Medium-Term Scheduler
1 It is
a job scheduler It is a CPU
scheduler It is a process swapping
scheduler.
2 Speed
is lesser than short term scheduler Speed
is fastest among other two Speed is in
between both short and long term scheduler.
3 It controls the degree of
multiprogramming It provides
lesser control over degree of multiprogramming It
reduces the degree of multiprogramming.
4 It is almost absent or minimal in time
sharing system It is also minimal in
time sharing system It is a part of
Time sharing systems.
5 It selects processes from pool and loads
them into memory for execution It selects
those processes which are ready to execute It
can re-introduce the process into memory and execution can be continued.
Context Switch
A context switch is the mechanism to store and
restore the state or context of a CPU in Process Control block so that a
process execution can be resumed from the same point at a later time. Using
this technique, a context switcher enables multiple processes to share a single
CPU. Context switching is an essential part of a multitasking operating system
features.
When the scheduler switches the CPU from executing
one process to execute another, the state from the current running process is
stored into the process control block. After this, the state for the process to
run next is loaded from its own PCB and used to set the PC, registers, etc. At
that point, the second process can start executing.

Context switches are computationally intensive since
register and memory state must be saved and restored. To avoid the amount of
context switching time, some hardware systems employ two or more sets of
processor registers. When the process is switched, the following information is
stored for later use.
• Program
Counter
• Scheduling
information
• Base
and limit register value
• Currently
used register
• Changed
State
• I/O
State information
• Accounting
information
A Process Scheduler schedules different processes to
be assigned to the CPU based on particular scheduling algorithms. There are six
popular process scheduling algorithms which we are going to discuss in this
chapter −
• First-Come,
First-Served (FCFS) Scheduling
• Shortest-Job-Next
(SJN) Scheduling
• Priority
Scheduling
• Shortest
Remaining Time
• Round
Robin(RR) Scheduling
• Multiple-Level
Queues Scheduling
These algorithms are either non-preemptive or
preemptive. Non-preemptive algorithms are designed so that once a process
enters the running state, it cannot be preempted until it completes its
allotted time, whereas the preemptive scheduling is based on priority where a
scheduler may preempt a low priority running process anytime when a high
priority process enters into a ready state.
First Come First Serve (FCFS)
• Jobs
are executed on first come, first serve basis.
• It is
a non-preemptive, pre-emptive scheduling algorithm.
• Easy
to understand and implement.
• Its
implementation is based on FIFO queue.
• Poor
in performance as average wait time is high.
Wait time of each process is as follows −
Process Wait
Time : Service Time - Arrival Time
P0 0 - 0 =
0
P1 5 - 1 =
4
P2 8 - 2 =
6
P3 16 - 3 =
13
Average Wait Time: (0+4+6+13) / 4 = 5.75
Shortest Job Next (SJN)
• This
is also known as shortest job first, or SJF
• This
is a non-preemptive, pre-emptive scheduling algorithm.
• Best approach
to minimize waiting time.
• Easy
to implement in Batch systems where required CPU time is known in advance.
• Impossible
to implement in interactive systems where required CPU time is not known.
• The
processer should know in advance how much time process will take.
Wait time of each process is as follows −
Process Wait
Time : Service Time - Arrival Time
P0 3 - 0 =
3
P1 0 - 0 =
0
P2 16 - 2 =
14
P3 8 - 3 =
5
Average Wait Time: (3+0+14+5) / 4 = 5.50
Priority Based Scheduling
• Priority
scheduling is a non-preemptive algorithm and one of the most common scheduling
algorithms in batch systems.
• Each
process is assigned a priority. Process with highest priority is to be executed
first and so on.
• Processes
with same priority are executed on first come first served basis.
• Priority
can be decided based on memory requirements, time requirements or any other
resource requirement.
Wait time of each process is as follows −
Process Wait
Time : Service Time - Arrival Time
P0 9 - 0 =
9
P1 6 - 1 =
5
P2 14 - 2 =
12
P3 0 - 0 =
0
Average Wait Time: (9+5+12+0) / 4 = 6.5
Shortest Remaining Time
• Shortest
remaining time (SRT) is the preemptive version of the SJN algorithm.
• The
processor is allocated to the job closest to completion but it can be preempted
by a newer ready job with shorter time to completion.
• Impossible
to implement in interactive systems where required CPU time is not known.
• It is
often used in batch environments where short jobs need to give preference.
Round Robin Scheduling
• Round
Robin is the preemptive process scheduling algorithm.
• Each
process is provided a fix time to execute, it is called a quantum.
• Once a
process is executed for a given time period, it is preempted and other process
executes for a given time period.
• Context
switching is used to save states of preempted processes.
Wait time of each process is as follows −
Process Wait
Time : Service Time - Arrival Time
P0 (0 - 0)
+ (12 - 3) = 9
P1 (3 - 1)
= 2
P2 (6 - 2)
+ (14 - 9) + (20 - 17) = 12
P3 (9 - 3)
+ (17 - 12) = 11
Average Wait Time: (9+2+12+11) / 4 = 8.5
Multiple-Level Queues Scheduling
Multiple-level queues are not an independent
scheduling algorithm. They make use of other existing algorithms to group and
schedule jobs with common characteristics.
• Multiple
queues are maintained for processes with common characteristics.
• Each
queue can have its own scheduling algorithms.
• Priorities
are assigned to each queue.
For example, CPU-bound jobs can be scheduled in one
queue and all I/O-bound jobs in another queue. The Process Scheduler then
alternately selects jobs from each queue and assigns them to the CPU based on
the algorithm assigned to the queue.
Shell
The shell is the command prompt within Linux where
you can type commands. If you have logged into a machine over a network (using
ssh or telnet) then the commands you entered were run by the shell. If you are
logged in using a graphical interface then you will may need to open a terminal
client to see the shell. There are several different terminal clients available
such as xterm, konsole and lxterm, or it may be just named Terminal Emulator.
It's location in the menu differs between different distributions if the start
menu allows searching (most do, but not all) then type term and it should show
an appropriate terminal, if not then look under the system or utilities menu.
Windows users may be familiar with the concept of a
command prompt, or DOS prompt, which looks similar to a UNIX shell. The UNIX
shell has more features and is practically an entire programming language,
although don't let that put you off as you can use the shell without any
programming ability. Even if you don't "do programming" you may find
that's it's worth learning a little bit of shell script programming as it can
be used to make your life easier.
Often people seeing the shell will think that this
is the UNIX / Linux operating system. It is in fact a program that is running
on top of the operating system. To take a basic view of how Linux is built up
see the diagram below:
The different layers of the Linux operating system
The kernel is the heart of the operating system.
This is the bit that is actually Linux. The kernel is a process that runs
continuously managing the computer. The kernel is a very specific task so to
allow programs to communicate with it there are a number of low level utilities
that provide an interface between the application and the kernel.
The shell is an application that allows users to
communicate with the computer. It is a text based application that allows
programs to be started and tasks to be run. The shell is within a collections
of utilities known as GNU. Without the kernel the computer cannot run and
without the GNU utilities it can't do anything useful which is why the
operating system is sometimes called GNU/Linux; although this ignores the host
of other applications that are also included (for brevity I am just using Linux
to mean everything included on the Linux distribution).
The
Different Shells
In the same way that different variants of UNIX were
developed there are also different variants of the shell.
Here's a list of the most common UNIX shells:
Name of shell Command
name Description
Bourne shell sh The most basic shell available on all UNIX
systems
Korn Shell ksh
/ pdksh Based on the Bourne shell with
enhancements
C Shell csh Similar to the C programming language in
syntax
Bash Shell bash Bourne Again Shell combines the advantages of
the Korn Shell and the C Shell. The default on most Linux distributions.
tcsh tcsh Similar to the C Shell
Common Linux / UNIX shells
When you login to a Linux machine (or open a shell
window) you will normally be in the bash shell.
You can change shell temporarily by running the
appropriate shell command. To change your shell for future logins then you can
use the chsh command. This is normally setup to only allow you to change to one
of the approved shells listed in the /etc/shells file. If you change your shell
for future sessions this is stored in the /etc/passwd file.
The shell is more than just a way of typing commands.
It can be used to stop, start, suspend programs and by writing script files it
becomes a programming language in itself.
More details of the shells are listed below.
Bourne Shell - This is the oldest shell and as such
is not as feature rich as many of the other shells. It's feature set is
sufficient for most programming needs however it does not have some of the user
conveniences that are liked on the command line. There is no option to re-edit
previous commands or to control background jobs. As the bourne shell is
available on all UNIX systems it is often used for programming script files as
it offers maximum portability between different UNIX versions. Bash is fully
backwards compatible with the Bourne Shell so running the bourne shell on Linux
will often call the bash shell (using a link between the files).
Korn Shell - This is based on the Bourne shell. One
enhancement that is particularly useful is its command-line editing facility.
It is possible using either vi or emacs keys to recall and edit previous
commands. This is not as easy to use as some of the other shells, but work well
across a network or using a physical terminal (rare these days). It also has
more powerful programming constructs than the bourne shell, however these are
not as portable. To run the Korn shell you can run either ksh or pdksh from the
normal shell (assuming it is installed).
C Shell - The c shell syntax is taken from the C
programming language. As such it is a useful tool for anyone familiar with
programming C.
Bash Shell - The Bash shell is a combination of
features from the Bourne Shell and the C Shell. It's name comes from the Bourne
Again SHell. It has a command-line editor that allows the use of the cursor
keys in a more "user friendly" manner than the Korn shell. It also
has a useful help facility allowing you to get a list of commands by typing the
first few letters followed by the "TAB" key. It is the default shell
on most Linux distributions and unless otherwise specified is the shell used
for the future examples.
tcsh - This is a different shell that emulates the C
Shell. It has a number of enhancements and further features even than the bash
shell.
The Shell Prompt
When logged into the shell you will normal see one
of the following prompts: $, % or #. This is an indication that the shell is
waiting for an input from the user. The prompts can be customised but generally
the last character should be left as the default prompt character as it helps
to indicate which shell you are running and whether or not you are logged in as
root.
The Bourne, Korn, and Bash shells all use a similar
syntax. Unless you are using one of the advanced features you do not
necessarily need to know which one of them you are in. If however you are in
the C or tcsh shells this uses a completely different syntax and can require
commands to be entered differently. To make it a little easier these have two
different prompts depending upon the shell.
The
default prompts are:
$ - Bourne, Korn and Bash Shells
% - C Shell
When logged into the computer as root (which is the
adminstrator username), you should take great care over the commands that are
entered. If you enter something incorrectly you could end up damaging the Linux
installation files or even delete all the data from a disk. For this reason the
prompt is different when logged in as a root user as a constant reminder of the
risks.
The default prompt for root is the hash sign # this
is regardless of the shell being used.
Login Settings for the Bash Shell
When you login to a shell a number of variables and
settings are configured for your shell. The files that are most commonly used
by bash are:
1. /etc/profile
2. ~/.bash_profile
3. ~/.bashrc
4. ~/.bash_logout
These files are text based shell scripts that can be
used to define settings for either system wide settings (those in the /etc
directory), or for an individual user (those in the users home directory
specified by ~). Different files are called depending upon whether it is an
interactive login shell or a non-interactive shell.
Bash as an Internactive Login Shell
The following is followed if bash is invoked as an
interactive login shell, or as a non-interactive shell with the --login option.
First the shell reads and executes commands from the
file '/etc/profile', if that file exists. After reading that file, it looks for
'~/.bash_profile'. If this is not found then it can instead use
'~/.bash_login', or '~/.profile'. The `--noprofile' option may be used when the
shell is started to inhibit this behavior.
The .bash_profile file is normally configured so
that it also calls the ~/.bashrc file (if it exists) towards the end of the
.bash_profile.
When the login shell exits, Bash reads and executes
commands from the file `~/.bash_logout', if it exists.
Bash as an Interactive Non-Login Shell
The following is followed when an interactive shell
that is not a login shell is started (e.g. if switching user or launching from
inside a shell). Bash reads and executes commands from '~/.bashrc', if that
file exists. This may be inhibited by using the `--norc' option. The `--rcfile
file' option will force Bash to read and execute commands from file instead of
`~/.bashrc'.
Bash as a Non-Interactive Shell
If bash is run as a non-interactive shell then the
scripts are not called, unless the -login option is used. If there is a script
given in the BASH_ENV variable then this will be run.
Normally the PATH variable is not set for any
non-interactive shells so when running tasks in a non-interactive shell
commands should be called using their full path names.
/etc/profile
The /etc/profile file provides the system wide
default environment variables. Typically this sets up the umask, LOGNAME, and
mail directories etc. It can also be used to change the default command search
path (PATH) for all users on the system. As most systems don't have a
/etc/bashrc file aliases are sometimes included in the /etc/profile file.
~/.bash_profile
This provides the user specific environment
variables, and is often used to add local search paths onto the PATH. This is
called after the /etc/profile script.
~/.bashrc
This file is called for non-interactive shells, and
is normally called from the ~/.bash_profile for interactive shells. It is
normally used for setting up aliases and any other commands that are run during
the startup.
~/.bash_logout
The ~/.bash_logout script is called when the user
logs out of the interactive shell.



No comments